Open新模型:丝滑如真人,GPT-4o引领交互革命
Open新模型:丝滑如真人
在5月14日的线上“春季更新”活动中,美国OpenAI公司揭晓了其新旗舰模型——GPT-4o,标志着在人机交互领域的重要进展。这一模型不仅能够实时处理音频、视觉和文本信息,还显著提升了ChatGPT处理多语言的能力,同时加快了响应速度并优化了输出质量。
GPT-4o的名字中,“o”代表“omni”,寓意“全能”,灵感来源于拉丁语,强调了模型跨多种媒介输入输出的全面性。它能够接受文本、图像和音频的综合输入,并灵活生成多种形式的输出,尤其在图像和音频理解上展示出超越前代的卓越性能。例如,GPT-4o能迅速理解音频中的情绪线索,如急促的喘息声,并给予相应指导,还能根据需求调整语调,以及实时解决数学问题和分析代码、图表。

相比之前版本,GPT-4o对音频输入的反应时间缩短至232毫秒,接近人类交流的速度,并大幅减少了信息损失,使得交互更加自然流畅。在图像处理上,通过摄像头输入的实时指令,ChatGPT也能顺利完成,展现了其在多模态应用上的强大潜力。Open新模型:丝滑如真人。
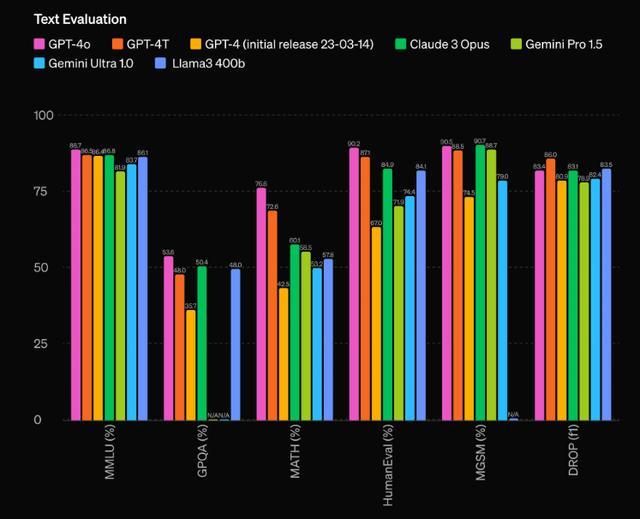
OpenAI透露,GPT-4o是他们首个集成了文本、视觉、音频处理的模型,目前正处于功能探索阶段,但已显示出在多语言、音频和视觉任务上前所未有的性能水平,与GPT-4 Turbo在基准测试中表现相当。
对于用户而言,OpenAI宣布正逐步向不同层级的用户提供GPT-4o服务,包括ChatGPT Plus、Team及企业用户,同时也推出了带有使用限制的ChatGPT Free版本。免费用户虽有额度上限,但依然能体验到GPT-4o的部分功能,超出限额后系统将自动转回GPT-3.5。此外,macOS平台的ChatGPT桌面应用也已面世,方便用户快速互动和分享内容。Open新模型:丝滑如真人。
活动最后,OpenAI的首席技术官Mira Murati对团队及合作伙伴英伟达表达了感谢,特别是英伟达提供的先进GPU技术,为当天的演示提供了强大支持。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rllx.cn/uOgO/28833.gov.cn
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈邮箱:809451989@qq.com,一经查实,立即删除!相关文章
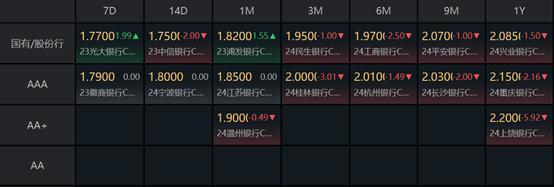
超长期特别国债来了 债市迎利好,长债利率料回归

韩系在中国为什么不火了 中国智造与供应链变革的双重影响

市民称希望郭有才能带动家乡发展 菏泽换新颜引热议

台退役将领帅化民江西祭祖:用脚步丈量感知家乡

菲方对中方的指责毫无根据纯属造谣 外交部严正驳斥

上海两车剐蹭后双方对骂 如何妥善处理交通事故纠纷

散户抱团股”卷土重来?游戏驿站引领避风港行情

韩国第一夫人收包案行贿人受审 牧师辩称曝光总统夫妇真面目

石锤落地!大华被暂停从事证券服务业务6个月,这些在会项目或受影响

北京将大力推广新能源车充新能源电 助力绿色出行新时代

李承铉让Lucky等弟弟长大后再收拾 二胎教育引共鸣
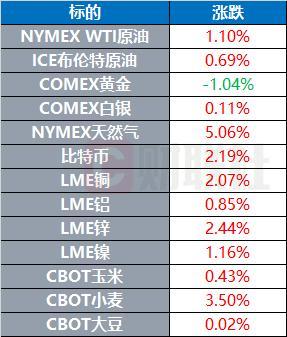
乌总统解除乌对外情报局第一副局长职务 影响国家安全决策?
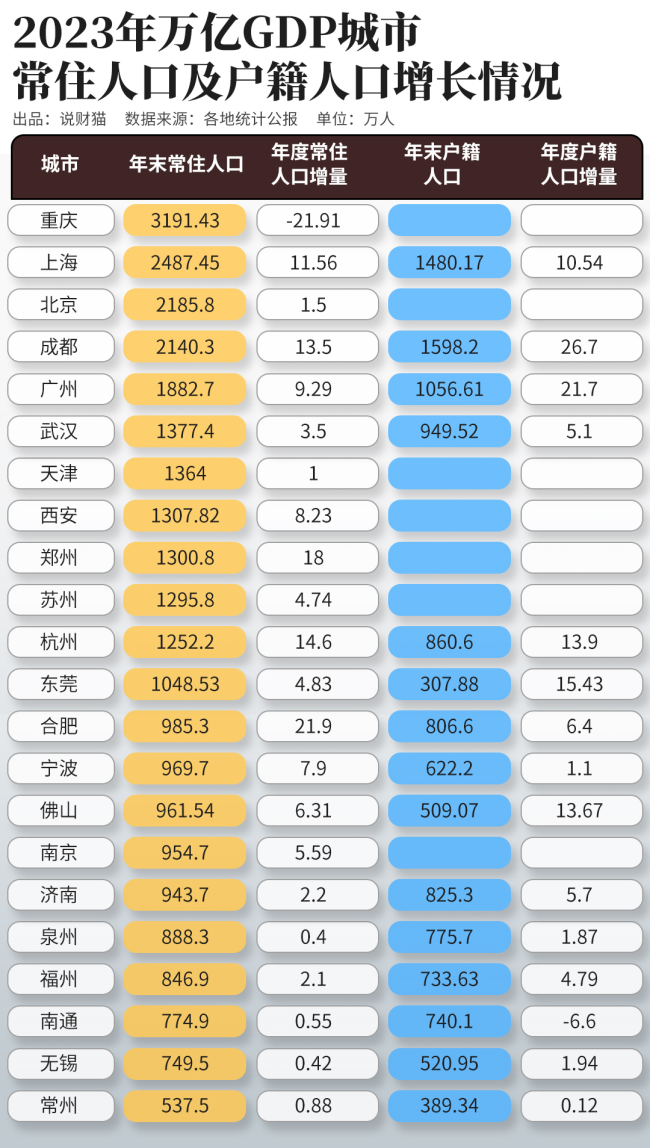
房地产,历史性改变 新房时代,颠覆来临!

OpenAI发布GPT4O 更快更便宜,重塑人机交互界
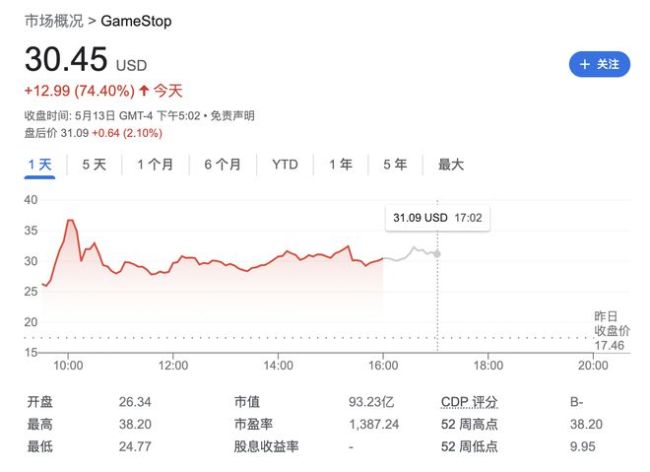
美股收盘:道指终结八连涨,游戏驿站一度狂飙近120%,中概大涨

大连有人给树喷“绿漆” 实为叶绿肥,非喷漆引误会
徐怀钰演唱会上自己调侃上座率 幽默化解尴尬,温暖满场
麦当劳中国声明 严查食品安全问题,确保操作规范

GPT4o将免费使用 全能AI助手革新交互体验