OpenAI新模型:图文音频全搞定,GPT-4o引领交互新时代
OpenAI新模型:图文音频全搞定
在周二凌晨1点的春季发布会上,OpenAI继“文生视频模型”Sora后再次为市场带来新惊喜。公司CTO米拉·穆拉蒂揭晓了与ChatGPT相关的多项更新,核心内容包括两大方面:一是推出了升级版的GPT-4o多模态大模型,该模型在速度与成本上优于GPT-4 Turbo;二是宣布ChatGPT免费用户也能享用GPT-4o模型,进行复杂数据分析、图像解析、在线搜索及应用商店访问等,预示着GPT应用商店即将迎来用户量的激增。
针对不同用户群体,OpenAI调整了消息限制策略,付费用户将享有更高额度的消息发送权限,而免费用户在配额耗尽后,系统会自动切换至GPT-3.5。未来一个月左右,Plus用户还将迎来基于GPT-4o优化的语音体验,尽管当前API尚未集成语音功能。此外,专为macOS设计的ChatGPT桌面应用即将面世,Windows版本预计年内推出,便于用户通过快捷键互动提问。

米拉·穆拉蒂强调,此次发布标志着公司在易用性上取得重要进展。在演示环节,GPT-4o展现了实时语音交互、情绪感知及多语言翻译等能力,如通过语音识别用户的紧张情绪并给予放松建议,以及实时提供数学问题解答等。GPT-4o还能检测面部表情以判断情绪,并有望与代码库互动,进行数据分析与图像解读。OpenAI新模型:图文音频全搞定。
OpenAI透露,GPT-4o的文本、图像输入功能即日上线,而语音和视频功能预计在未来几周内加入。尽管市场上关于生成式AI的投入与日俱增,2023年已达291亿美元,且预计市场规模将持续膨胀,但也引发了对技术偏见及未经充分测试服务快速普及的担忧。
自2022年11月亮相以来,ChatGPT用户量飞速增长,现接近1亿周活跃用户,深受《财富》500强企业青睐。穆拉蒂承诺,未来数周内,这些创新功能将面向大众开放。她还特别感谢了英伟达提供的先进GPU技术支持。
OpenAI介绍,GPT-4o在音频响应速度上实现了显著提升,最快可在232毫秒内作出反馈,更接近人类对话节奏。此模型整合了文本、音频、图像处理能力,为自然人机交互带来了质的飞跃。虽然目前仍处于探索阶段,GPT-4o展现的潜力预示着AI技术在多模态交互上迈出了重要一步。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rllx.cn/RnuO/28897.gov.cn
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈邮箱:809451989@qq.com,一经查实,立即删除!相关文章

郭有才:不介意各地出现我的模仿者,带动网红经济热潮

庆余年2举办超前巡映礼 角色成长引热议,5月16日双平台首播

新政后杭州楼市外地看房客激增 楼市回暖迹象初显

路人摸车被索赔1万元?警方通报 事件澄清,造谣者被拘

广西媳妇远嫁浙江农村感叹幸福指数太高了 就近务工,公婆贴心。
麦当劳被指篡改食品保质期标签 食品安全引质疑

预售制被主流电商平台抛弃 大促新策略重塑消费体验
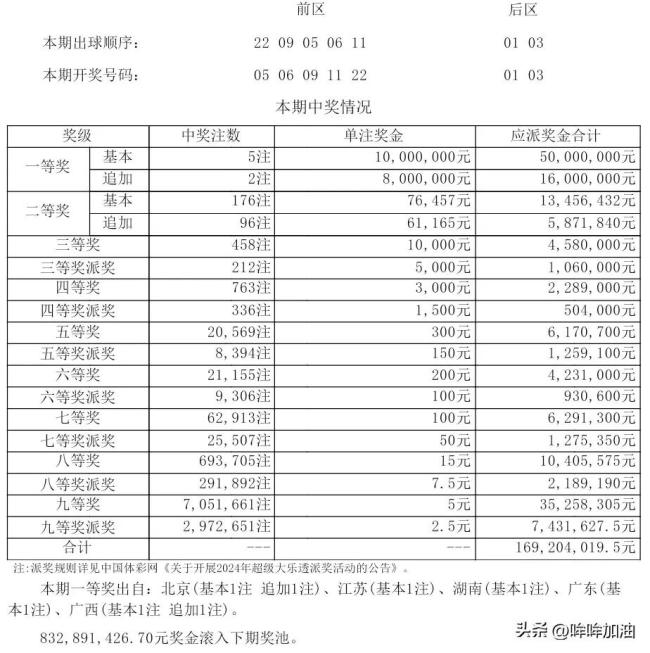
大乐透开出5注千万大奖 奖池余8.32亿 美好期待迎未来精彩

知名感冒药999复方感冒灵颗粒缺货 产能不足引关注
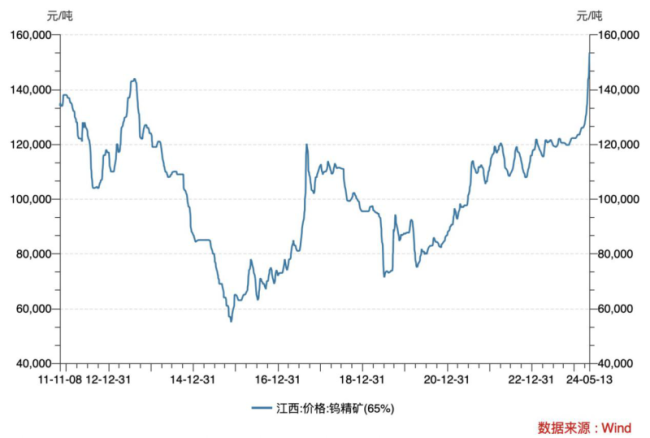
钨价“高烧”:供不应求下冲至十年新高,一天涨千元
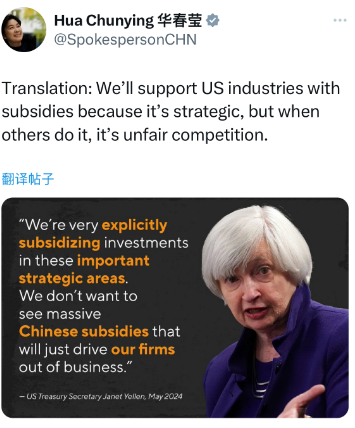
耶伦炒中国产能过剩被美主持人质疑 美国补贴何其多?
国际观察|以色列为何一意孤行扩大在拉法军事行动

媒体:正当执法应桥归桥路归路,拒绝碰瓷式执法
媒体谈碰瓷执法:若没有行车记录仪呢?活久见的离奇一幕

治理高额彩礼为婚嫁减负 构建健康婚恋新常态

安徽省林业局回应东北虎死亡事件 彻查到底,绝不包庇;官方介入调查

普京为何要任命经济学家担任新防长 军事与经济的深层考量
OpenAI新模型可读取用户情绪 对话未来情感智能

台祖孙三口灭门案涉案女婿落网 残忍行径引众怒
