大模型“高考”考生数学都不及格 语文英语显优势,数学能力待加强
高考,作为一项涵盖广泛学科和题型的考试,因其考前的高度保密性,被视为中国最具权威性的测试之一。近期,它成为了评估高级人工智能模型智力水平的重要工具。上海人工智能实验室的OpenCompass平台挑选了7个顶尖的人工智能模型,让它们参加了包括语文、数学、英语在内的全科目模拟高考。
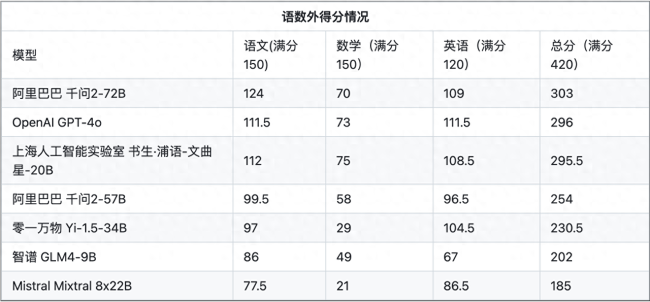
测试结果于6月19日公布,阿里通义千问2-72B以303分的总分位居榜首,紧接着是OpenAI的GPT-4o,得分为296分,而上海人工智能实验室的书生·浦语2.0则获得第三名。这三个模型的得分均超过了70%的及格线,而法国初创公司Mistral的模型则排名最后。
参与这次测评的模型涵盖了国内外多家企业和机构,既有开源的也有如GPT-4o这样的闭源模型。值得注意的是,为了确保公平性,仅选取了在考前已公开的模型,避免了可能的针对性训练。
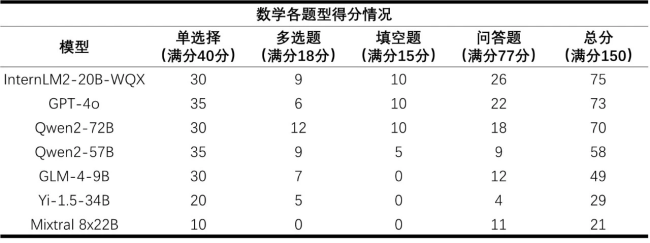
测试显示,尽管这些大模型在语文和英语科目中表现出色,但它们的数学成绩普遍不佳,无一及格。其中数学最高分75分出自书生·浦语2.0,GPT-4o紧随其后,得了73分。语文最高分归于通义千问,而英语则是GPT-4o领先。
数学成为大模型面临的一大挑战,它要求复杂的推理能力,这对于模型在金融、工业等领域实现可靠应用至关重要。上海人工智能实验室的领军人物林达华指出,复杂推理直接关联到模型在诸如金融场景中的数据准确性,以及处理专业文档时的精确计算能力,这些是当前大模型应用向更严肃商业环境扩展的障碍。
此次评测遵循全国新课标I卷的标准,全面考核了客观题与主观题,由具有高考阅卷经验的教师匿名评分。阅卷过程中,教师们并不知道回答来自AI模型,以确保评价的公正性。然而,大模型的错误模式与人类不同,这给教师评分带来一定挑战,故每题至少由三位教师评分并取平均值,对于评分差异大的题目还进行了复核。
阅卷完成后,教师们得知他们评分的对象实为AI模型,并受邀对模型的表现进行了综合分析,为未来模型的改进提供了方向。教师们的反馈揭示了模型在各个科目上的强项与不足:模型在现代文阅读理解上表现良好,但在文言文理解和作文创意表达上显现出局限;数学解题虽能记忆公式,却缺乏灵活运用;英语虽总体表现良好,但在特定题型和作文字数控制上仍有待提高。此外,由于电子文本的特性,作文评分可能存在细微的主观偏差。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rllx.cn/kWuC/56028.gov.cn
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈邮箱:809451989@qq.com,一经查实,立即删除!相关文章
苏格兰vs瑞士小组赛关键战:首发阵容出炉

男子酒后跟陌生女子玩游戏转账5万2 法院判返还,戏谑行为无效

玫瑰的故事最炸裂的台词出现了 性别平等警世钟声

俄朝领导人互赠了哪些礼物 友谊见证与战略意图

广西桂林遭遇1998年以来最大洪峰 超警2.55米,紧急转移69人

巴黎奥运女排分组:中美法同组,竞争激烈

方协文:你有精力工作没精力生儿子?玫瑰台词引共鸣

国际乒联公布奥运单打邀请名单 陈梦缺席引热议

FIBA洲际杯分组出炉 新加坡赛事9月上演

暴雨过后村民巧用龙骨水车排水!

欧冠预选赛第一轮抽签结果发布 诸强对阵出炉

欧洲杯最前线 英格兰赛前冒雨训练卢克肖缺席,下午前往法兰克福

盘点陈晓陈妍希近两年反常事!

记者:足协裁判评议制度真的不错

欧洲杯豪门球队谁最有“冠军相”!

真的建议报考上海交通大学 筑梦顶尖学府
李瑞峰称中国品牌不可以向下 长城汽车的自我革新之路

博主:淄博城管又火了

民进党为掩盖弊案涂黑调查资料!
